Faster Information Extraction from any document using Data Modeling Language
Visually Rich Documents are ubiquitous in nature and contain a lot of information. Examples of such documents include scanned or...


Visually Rich Documents are ubiquitous in nature and contain a lot of information. Examples of such documents include scanned or computer-generated invoices, bank statements, bills, medical documents, insurances etc. Hence, information extraction from such documents has become a hot research topic. Automatically recognising texts and extracting valuable information from documents can facilitate information entry, retrieval and compliance check and is of great benefit to office automation in areas like accounting, financial and much broader real-world applications.
This complex problem of understanding a document can be broken down into two subproblems of 1. Text reading and 2. Information Extraction. Text reading includes text detection and recognition, which belongs to the Optical Character Recognition research field and many solutions have been proposed in this domain. Google Vision is one such example of commercialised OCR, which offers powerful pre-trained machine learning models through REST and RPC APIs. Other such examples are tesseract, AWS textract etc.
Information Extraction on the other hand is mining relation between key-value pairs from plain text data. That means text reading is reading text data without semantic supervision. For Information extraction, several methods have been studied for decades such as rule-based method, pattern matching and template matching methods. Though rule-based methods work well for some cases, they highly rely on predefined rules. At Searce, we have employed template-based matching for information extraction. In our template matching method, we are considering layout information for keys and values while information retrieval.
Positioning and layout information for entities has been stored in a separate file for the given template via DML. The DML is envisioned as a tool for onboarding and extracting data from image-based documents with minimal effort. The focus is to make the onboarding process simple and fast.
Traditional vs DML
Traditional rule-based extraction required intense training and/or information extraction expertise. Moreover, whenever new document templates come, different pieces of rules need to be written, trained and tested, which consumes a lot of time for the customer as well as a developer as maintenance becomes harder as no of templates increase. Although this kind of solution produces excellent extraction results, it does not match with requirements for low configuration and high flexibility. A huge disadvantage of current trainable systems is the need for large sets of example documents, requiring manual annotations. In our approach of Data Modeling Language, a DML configuration file is prepared for a given template which is going to be used for information extraction from any document of that template type. This makes onboarding easier and faster without a need of having larger training data or waiting for days to finish it!
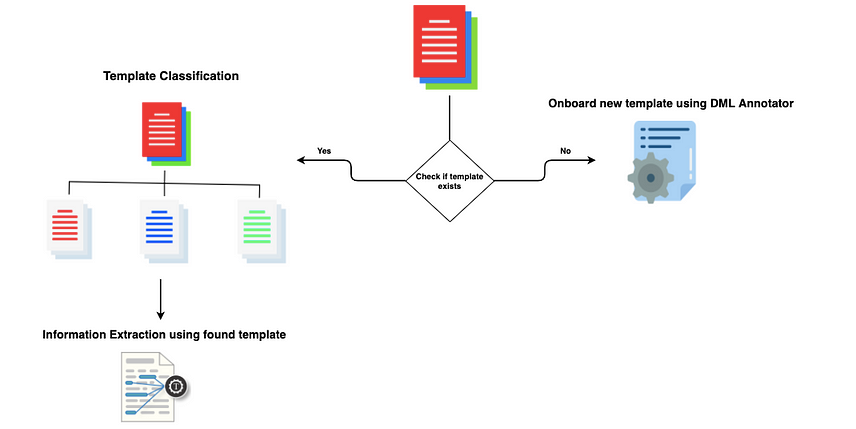
Approach
1. Data Annotator : Generate DML config for a template.
2. Template Classification : Classify input document based on template type.
3. Information Extraction : Employ generated DML config for Information Extraction from any document of that template.
Let me explain each step in detail…
1. Data Annotator
Like any other document processing system, we start with generating DML config for a given input template using the Data Annotator tool. We have used annotation UI to annotate key-value pairs and then the output file of this annotation tool has been converted into DML config file via data annotator module. Output of this step is a DML config file for any given template, that can be used immediately for information extraction. Faster and flexible isn’t it ?!
2. Template Classification
What happens if you have multiple different templates? In such a case we need a classification module which will classify a given input document to its template type, so that information extractor can choose a DML config file for that template properly from the data store. The template classification module integrates a one-shot learning process using a Siamese Network to classify input documents. The advantage of using a Siamese Network is that the classification can be done using a single reference image, thereby eliminating the need for a large training set.
3. Information Extraction
The information extractor module uses the template ID generated by the classifier to load the relevant DML config file. The config is generated by the annotator and contains rules for key-value extraction. This config file is used to extract information from text detected by Google Vision API. We rely on external OCR because of its superior recognition rates. Hence, OCR optimisations are not part of our work. Output of this stage is key-value pairs that you wanted to extract.
Limitations
If base OCR is not giving proper output then the Information extractor module will not be able to extract keys and values properly.
Currently, this approach is supporting keys and values extraction only, it does not support free flow text and table extraction.
Lastly, if keys and values get separated in different pages, that is if the page break is there, then the extractor module will not be able to extract keys and values.